In our ongoing series, Architecting Reliable Infrastructure in Azure: Mastering the WAF Reliability Pillar we've been exploring the pillars of Azure WAF (Well-Architected Framework) Mastering Azure Excellence: A Deep Dive into Operational Efficiency and Security and guiding you through the process of building a robust and reliable infrastructure with Azure. Ensuring the resilience of your Azure-based workloads is imperative for seamless operations. To achieve this level of reliability, it's essential to establish clear metrics and objectives that serve as your guiding lights in your journey toward a dependable Azure environment.
Establishing reliability metrics and objectives
In this segment, we'll delve deeper into the core components of establishing reliability metrics and objectives within the Azure Well-Architected Framework, outlining how they are vital to the success of the Organization.
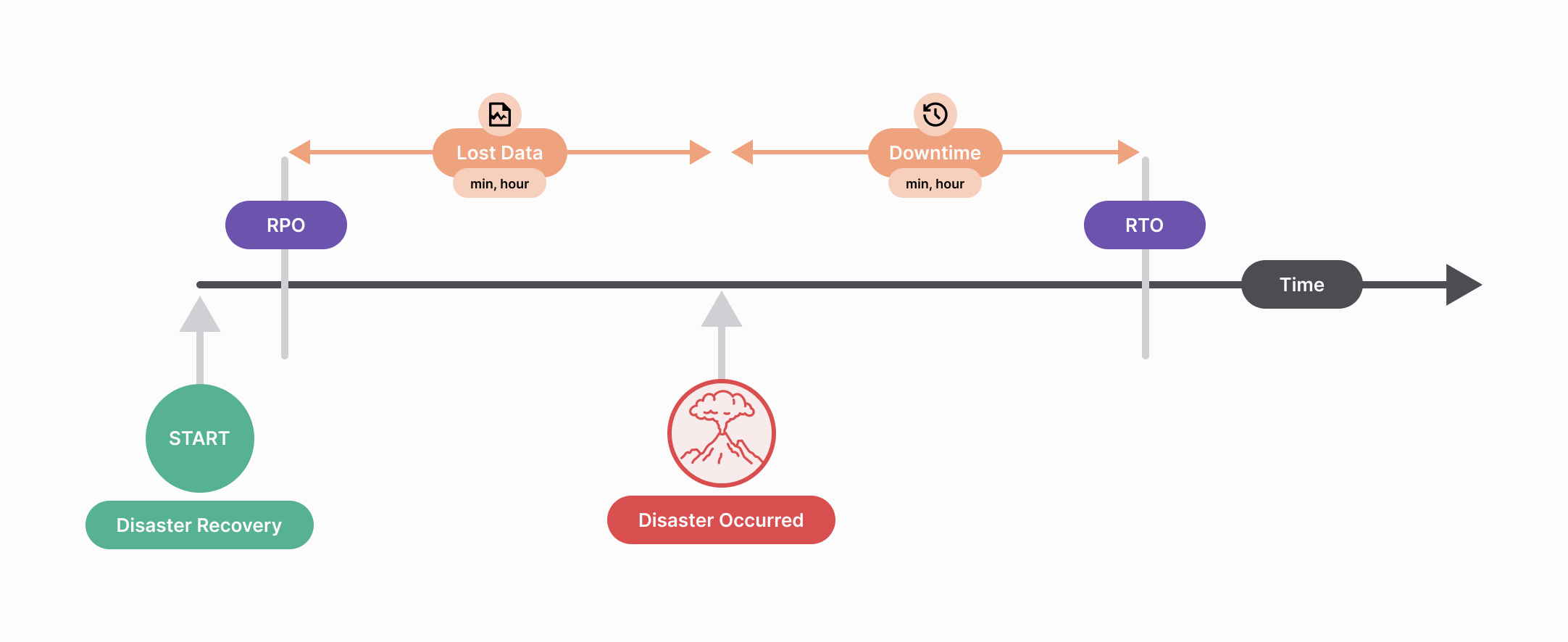
1. Recovery Time Objective (RTO) and Recovery Point Objective (RPO)
One of the foundational steps in your quest for reliability is determining your Recovery Time Objective (RTO) and Recovery Point Objective (RPO). RTO specifies how long your workloads can be unavailable in the event of a disaster, while RPO defines the allowable data loss during such an incident. These metrics are the bedrock of your disaster recovery planning, helping you establish precise tolerances for downtime and data loss specific to your workloads.
2. Availability Targets: SLAs and SLOs
Availability is at the core of reliability. Service Level Agreements (SLAs) and Service Level Objectives (SLOs) play a pivotal role in defining the availability of your Azure resources and the applications offered to your customers. Azure resources come with predefined SLAs, guaranteeing uptime for specific services. However, it's equally important for Your Organization to establish its SLAs for customer-facing services. Meeting or exceeding these availability targets is crucial for maintaining a reliable system.
SLAs are not just contractual agreements; they are the cornerstone of a successful relationship between you and your customers.
3. Composite SLA
It's essential to derive a composite SLA encompassing the Azure SLAs for all relevant resources. This consolidated SLA provides a holistic view of your system's expected availability. By understanding the composite SLA, you can ensure that your startup maintains the expected levels of reliability across the board.
Example composite SLA use case:
A company is developing a new e-commerce website. The website will use various Azure services, including App Service, SQL Database, and Azure Storage. The company wants to ensure that the website is available to customers 99.99% of the time.
To achieve this goal, the company creates a composite SLA that combines the SLAs of the individual Azure services.
The composite SLA is calculated as follows:
Composite SLA = App Service SLA * SQL Database SLA * Azure Storage SLAThe SLAs for the individual Azure services are as follows:
- App Service SLA: 99.95%
- SQL Database SLA: 99.99%
- Azure Storage SLA: 99.9999%
Therefore, the composite SLA for the e-commerce website is 99.95% * 99.99% * 99.9999% = 99.9994%.
In this case, you will not be able to provide an SLA better than 99.9994% since that's your composite SLA
4. SLAs for Dependencies
Beyond internal resources, consider the external dependencies that your software relies on. Establish SLAs for these dependencies to ensure that your startup's operations are not disrupted due to issues outside your immediate control. This proactive approach enables you to manage expectations and build redundancy plans where necessary.
This is like considering the external third party services like any Email service in your composite SLA
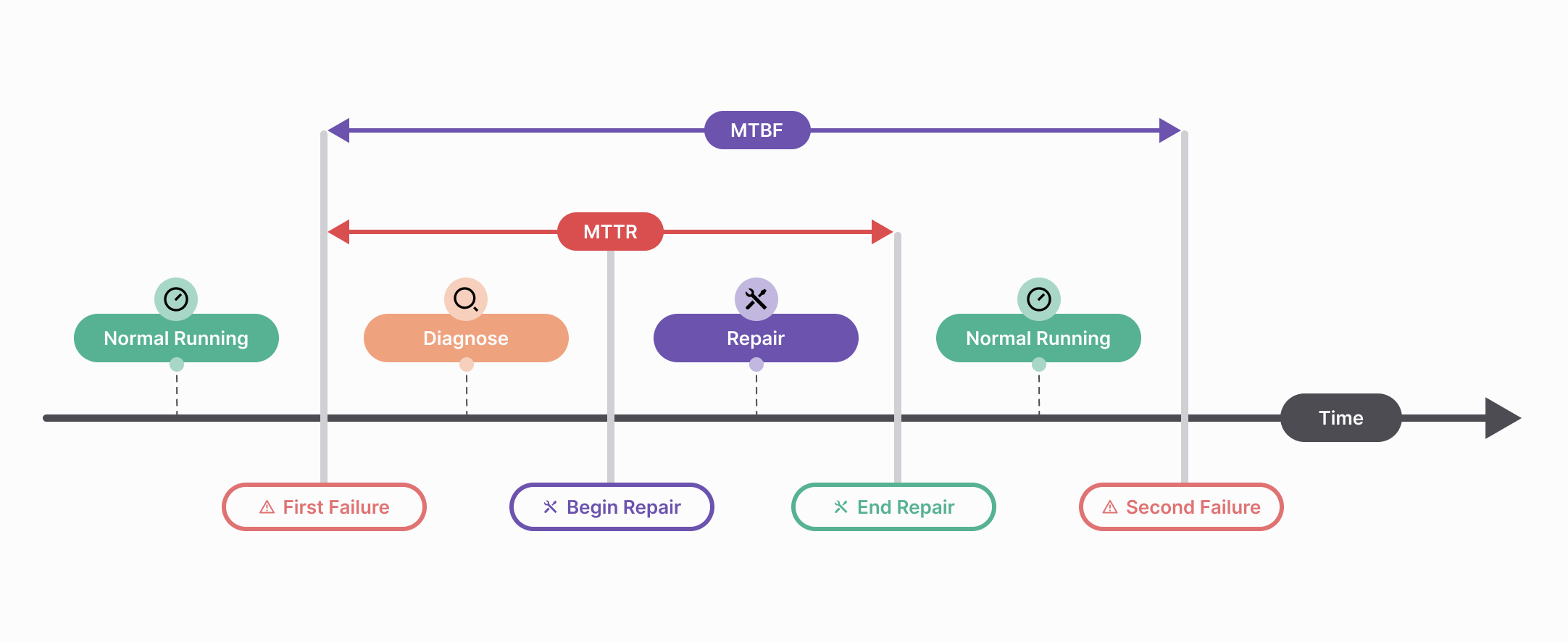
5. Availability Metrics: MTTR and MTBF
Monitoring and measuring the availability of your Applications is an ongoing process. Two fundamental metrics in this regard are Mean Time To Recover (MTTR) and Mean Time Between Failure (MTBF). MTTR represents the average time it takes to restore service after a failure, while MTBF quantifies the average time between failures. These metrics provide insights into the reliability of your workloads and help you make improvements as needed.
In conclusion, establishing reliability metrics and objectives within the Azure Well-Architected Framework is critical for an Organization's success. By defining clear RTO and RPO values, setting availability targets, measuring key metrics, and understanding composite SLAs, you can proactively work toward maintaining a highly reliable Azure-based infrastructure. Additionally, addressing SLAs for external dependencies ensures you are prepared for unforeseen challenges. Reliability is not just a goal; it's a mindset, and these metrics and objectives will help you achieve it for your Azure cloud-based startup.
Onepane's solutions complement this journey by providing tools and insights that empower Azure customers to optimize resources and handle incidents effectively, ensuring a reliable and seamless cloud experience. Let's see more of this in the coming part of this blog.
