We already discussed how to set Chaos Mesh in an environment and create a token to log in, we are discussing running Chaos experiments on a microservice application using Chaos Mesh. Chaos mesh supports various experiments like DNS Fault, Pod Fault, Stress Tests, and Network Attacks to test our environment or project. We can explore some of the experiments. Chaos Mesh supports both local and Kubernetes.
Chaos Mesh provides 3 major services
- Workflow
- Schedules
- Experiments
Workflow
A Chaos workflow combines Chaos experiments and application status checks, facilitating complete Chaos engineering projects on the platform. These workflows allow a series of Chaos experiments, expanding the impact scope and failure types. Post-execution, easily monitor the application's status via Chaos Mesh, deciding on follow-up experiments
Schedules
Schedule multiple experiments to chaos the project and experiments will run for specific durations at set time intervals. Customize experiments for different microservices.
Experiments
Similar to scheduled experiments, this is a one-time experiment. You can reload or replicate the same experiment from a previously completed one.
Type Of Chaos experiments
The following the chaos experiments provided by Chaos Mesh
- Pod Chaos : Simulates failures within Pods, including node restarts, persistent unavailability, and specific container failures.
- Network Chaos : Simulates network issues like latency, packet loss, disorder, and network partitions.
- DNS Chaos : Creates DNS failure scenarios like domain name parsing issues and incorrect IP address returns.
- HTTP Chaos : Simulates HTTP communication failures, such as HTTP communication latency.
- Stress Chaos : Simulates CPU race or memory race.
- IO Chaos : Simulates application file I/O failures, including delays, read, and write failures.
- Time Chaos : Simulates time jumps or time-related exceptions.
- Kernel Chaos : Simulates kernel failures, like application memory allocation exceptions.
- AWS Chaos : Replicates AWS platform issues, like node restarts within AWS infrastructure.
- GCP Chaos : Recreates GCP platform issues, like node restarts within the GCP infrastructure. JVMChaos: Creates JVM application failure scenarios, like delays in function calls.
Here I am using a Google online boutique project to run experiments, Clone the project from GitHub, and run it on localhost or Kubernetes, chaos mesh supports both localhost and Kubernetes.
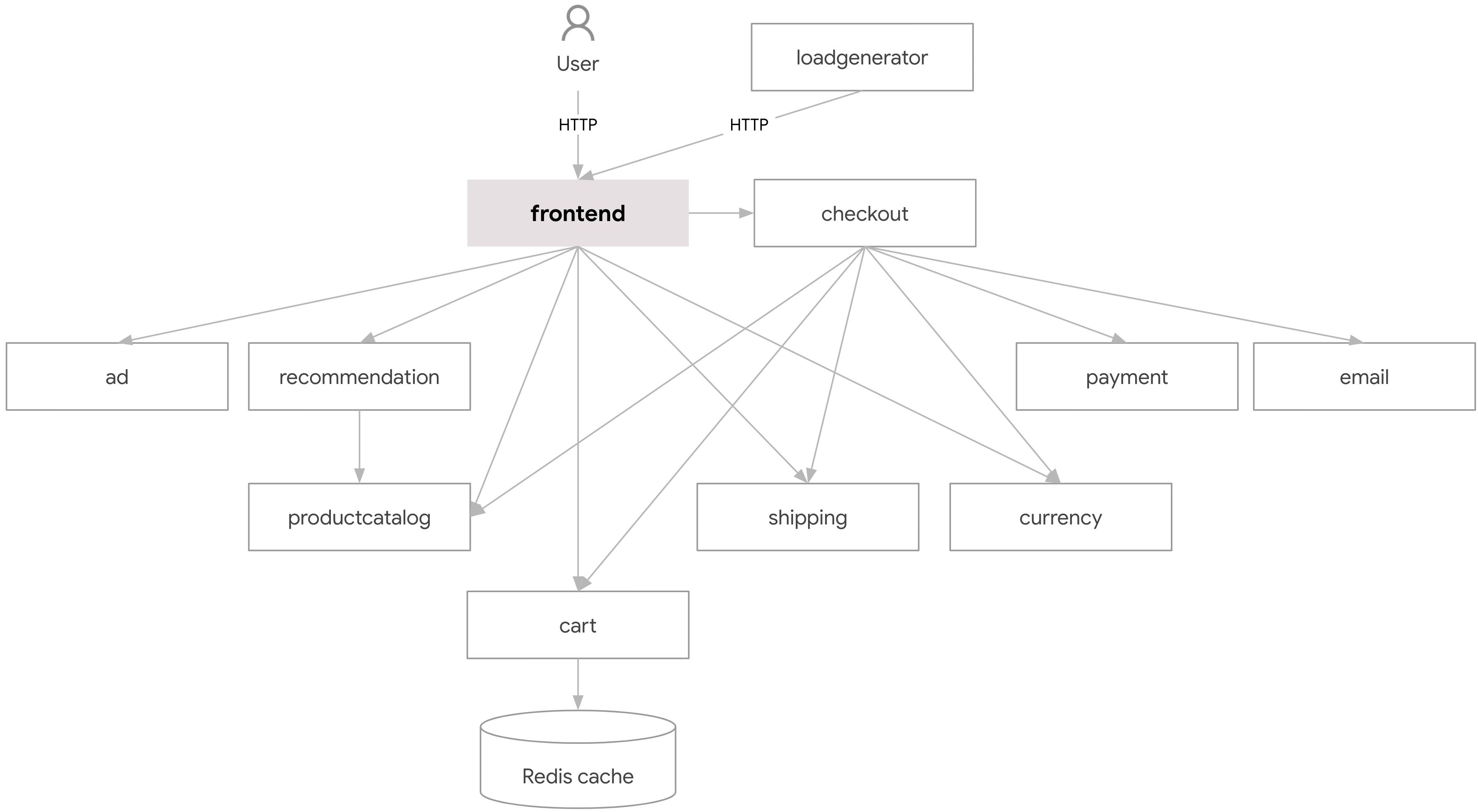
The online is a microservice project which having applications like ad service, and cart service. The online boutique architecture diagram shown below.
Let's Try an experiment
Try to break the recommendation service application. The whole application will run without any issues, but any part integrated with the product recommendation service might be affected. The following image is the experiment creation window of Chaos Mesh
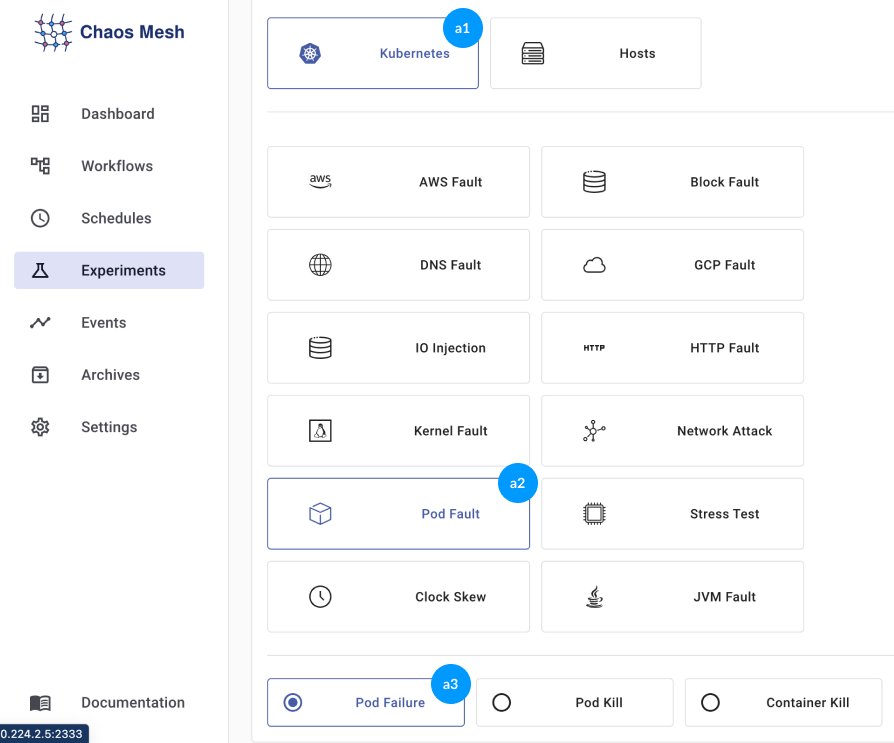
Step 1: Choose the environment type in section (a1)As I'm using Kubernetes, I've selected Kubernetes
Step 2: Selected the 'Pod Fault' operation from section (a2)
Step 3: Now, you can see three options (a3). Select 'Pod Failure'.
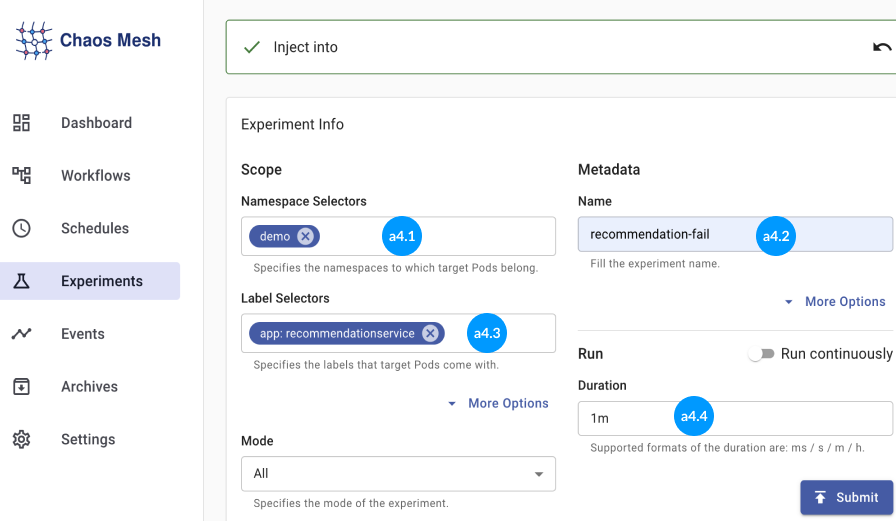
Step 4: Moving to the Experiment Info section (a4), Choose the namespace of the microservice application from the dropdown (a4.1).
Step 5: Select the label of the microservice application from the dropdown (a4.3). Step 6: You can set the experiment's runtime (a4.4) by adding 1m, 1h, or 1d, or you can simply check the 'Run continuously' option, which keeps the experiment running until manually stopped.
Step 7: Click the submit button to run the experiment.
Now the Product page is broken.
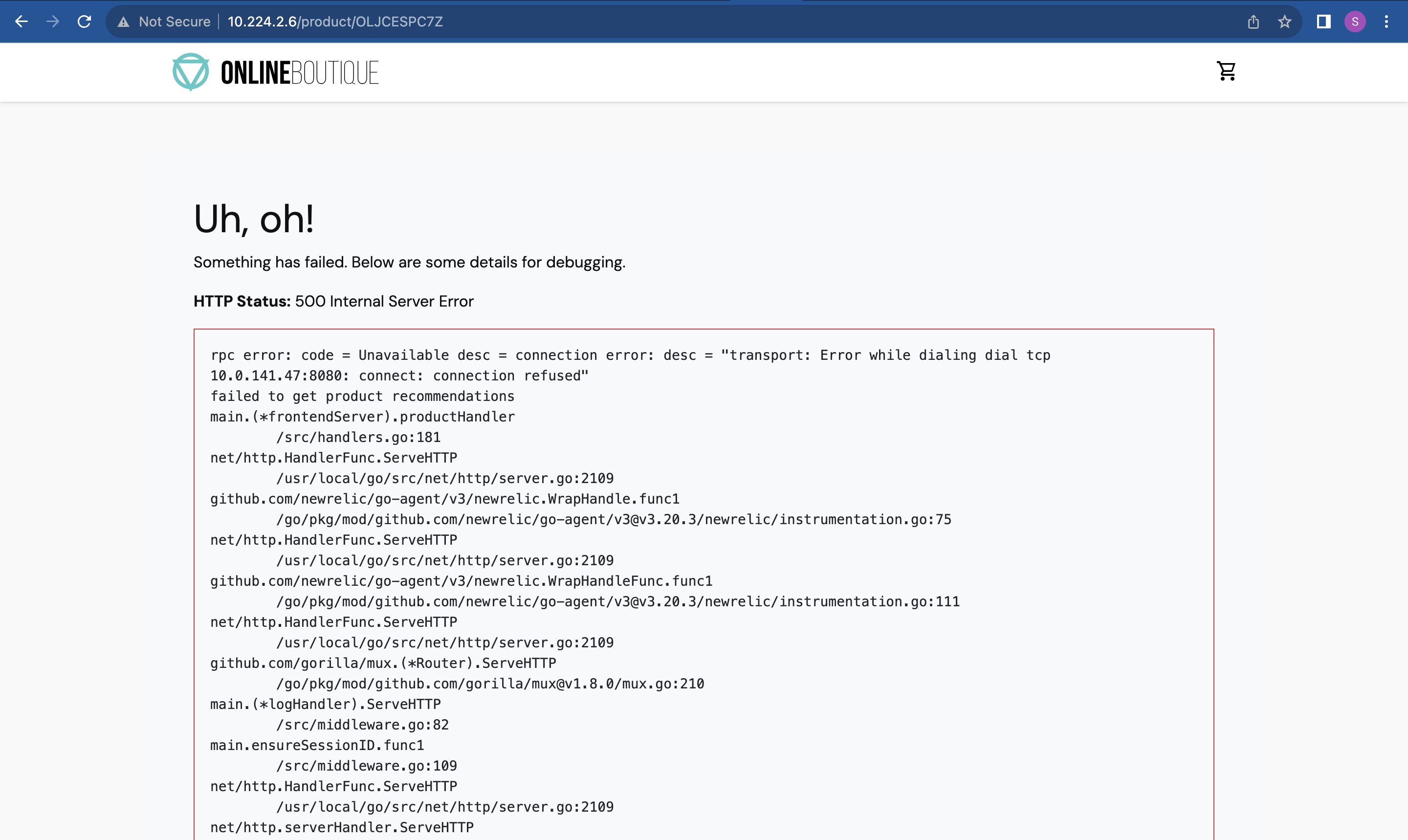
What caused the breakdown?
We conducted a pod termination experiment on the recommendation service. As you can see in the screenshot below, the recommendation service pod isn't ready. Consequently, when loading product details, attempts to access the recommendation service APIs fail due to the pod's unavailability.
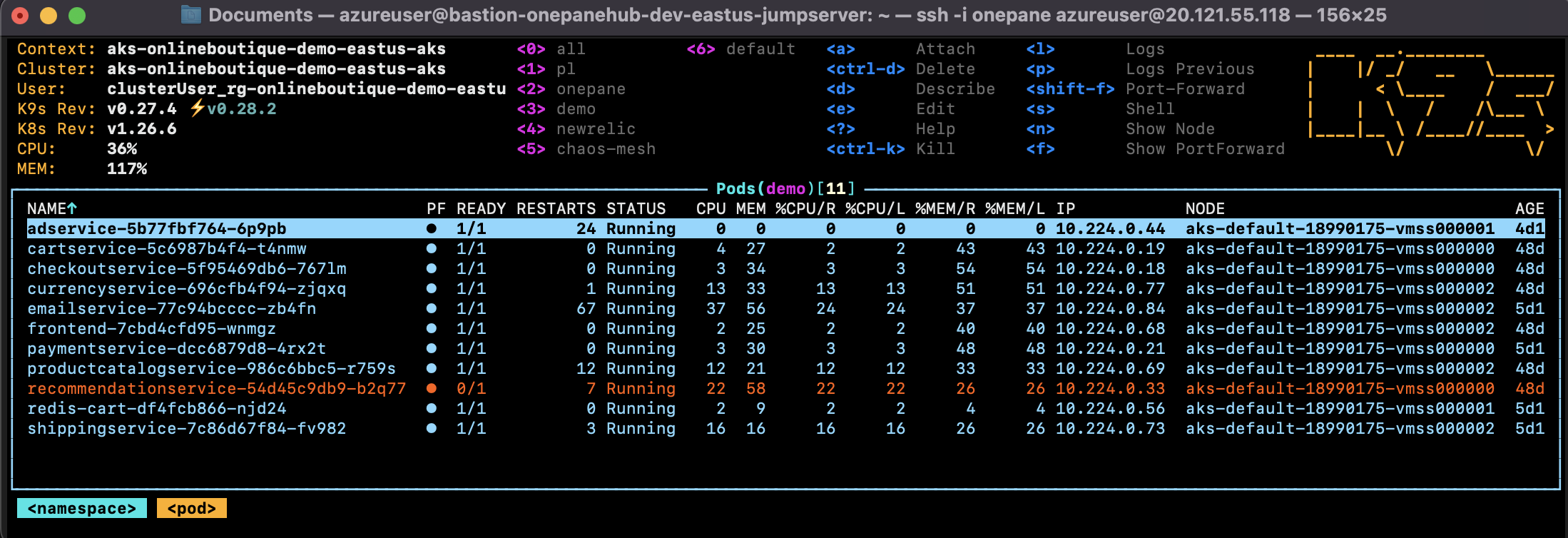
Same as we can run a "Pod Stress" experiment on "adservice".
Step 1: Selected the 'Stress Test" operation from section (a2)
Step 2: Presently, there are two choices available (a5): CPU and Memory. These options allow you to configure the number of Workers for both. Workers determine the number of jobs to exert stress on the pod. Step 3: Repeat the same steps 4, 5, and 6 for the "Pod Kill" experiment.
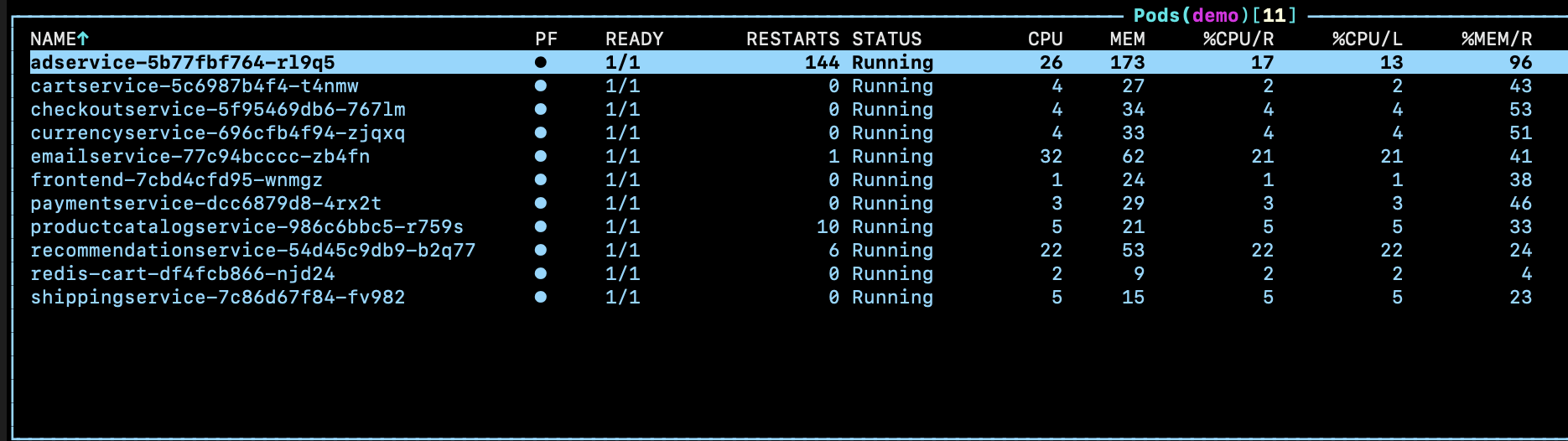
Here I selected 'adservice', and attached the screenshot of both the before and after CPU and Memory status of the adservice pod, before running the experiment, The pod had good CPU and memory.
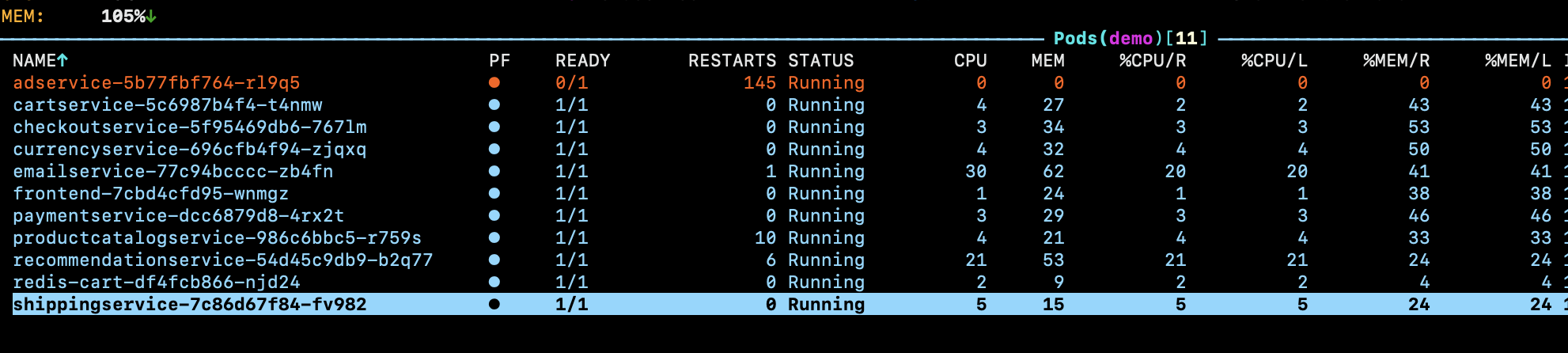
After running the experiment, The pod CPU and memory go down.
We've only attempted two experiments here. Chaos Mesh offers numerous experiments; explore further chaos experiments available within the Chaos Mesh platform By running diverse experiments, you can ensure the robustness of your application. For details of chaos mesh, explore the documentation
